我的目标是可视化一个Embedding矩阵的聚类效果,但是矩阵极大,维数也高。
具体来说就是矩阵是一个矩阵维度是459753*32,每一行对应一个向量,代表单元对应的UnitVector;矩阵对应的标签是459753个,每一个标签记录当前单元对应的其他信息(例如单元的时长、单元所属类别、单元对应的音频文件名),其中最关注的是UnitVector与单元所属类别的关系
也就是已知二进制文件UnitVector矩阵与标签文件
Mathematica
最开始采用的方法是Mathematica
tSNE
降维
1 | data=Import["../phone_name_frame_id.csv","Table"]; |
其中data[[All,2]]就是音素所属类别信息,Unit2Vec_UnitVector.dat是Embedding矩阵。
会输出两个文件
- 第一个Unit2Vec_tSNE.dat是459753*2的已经降维得到的矩阵,这在Javascript才用到的
- 第二个便于Mathematica可视化
可视化降维的分布
1 | byspecies=KeySort@Import["Visualization Phone Unit2Vec.wl"]; |
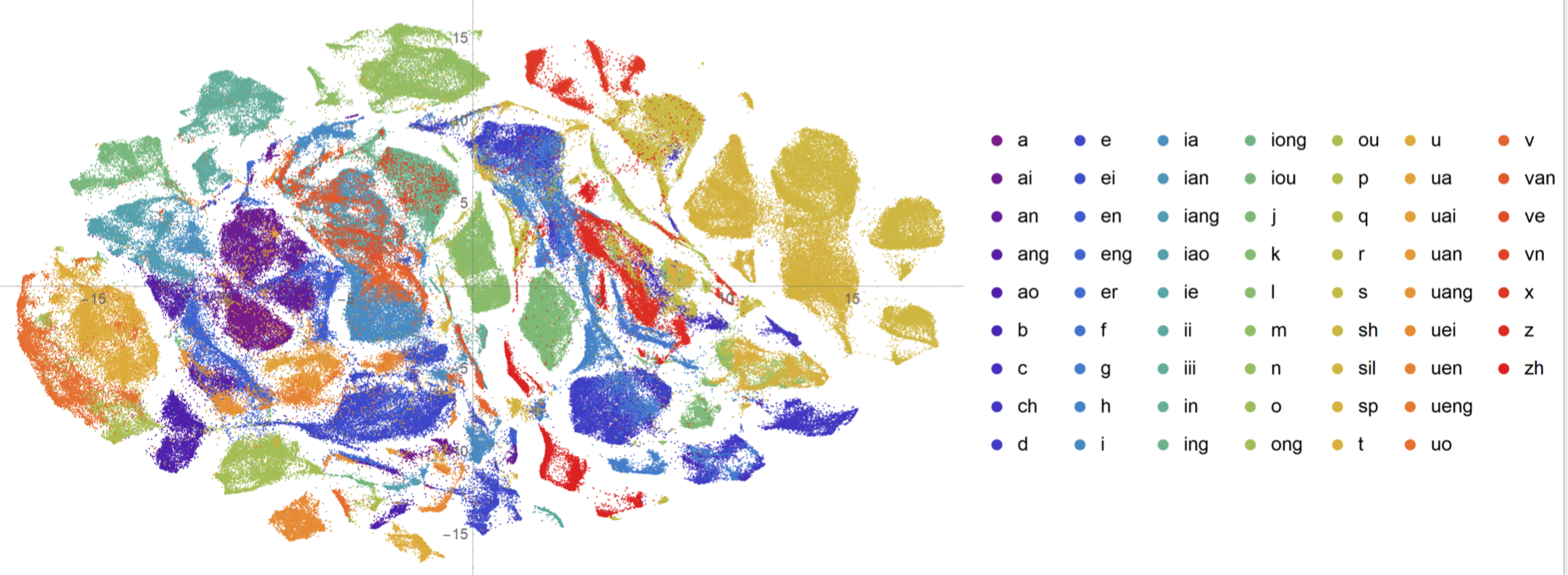
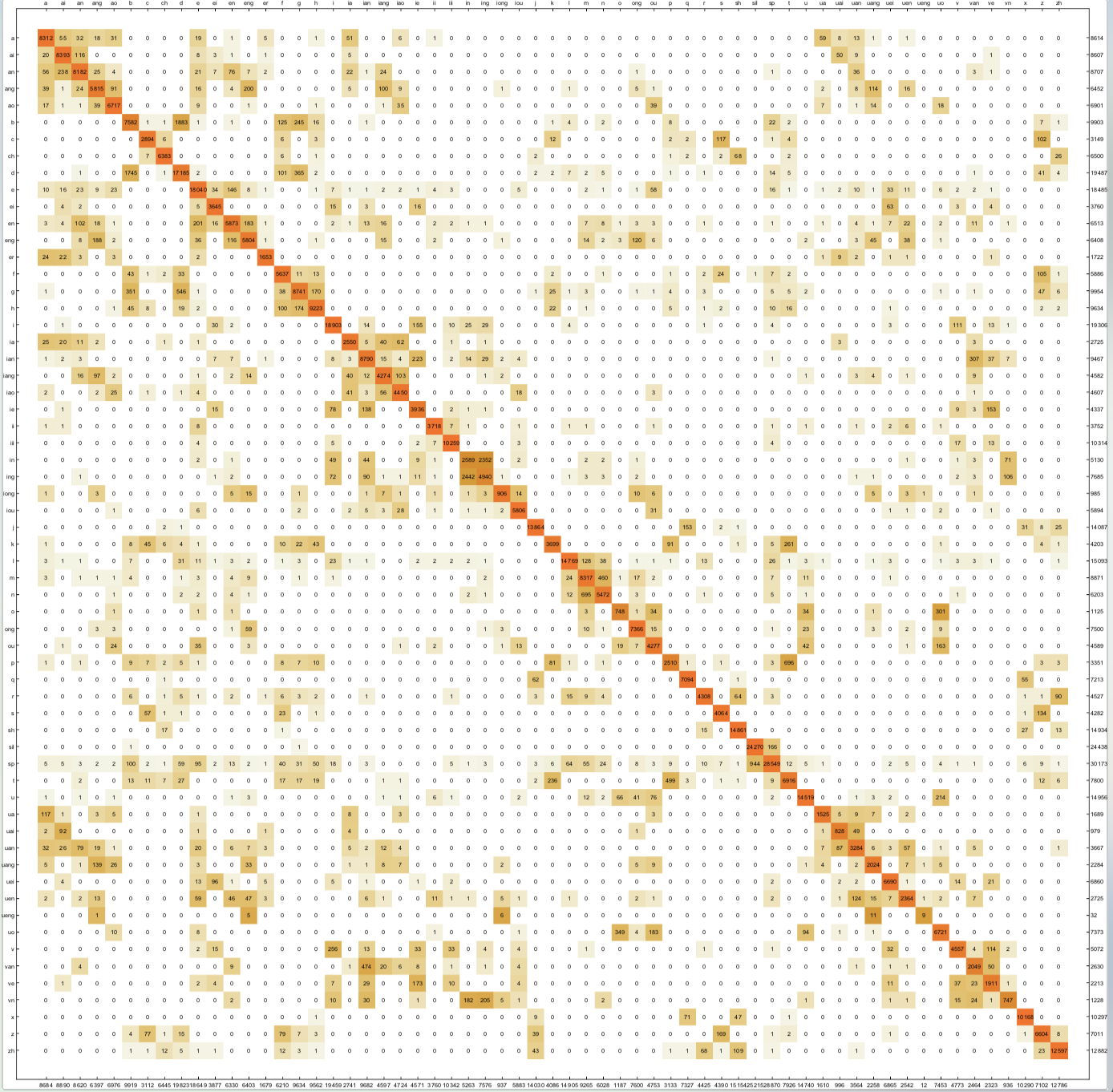
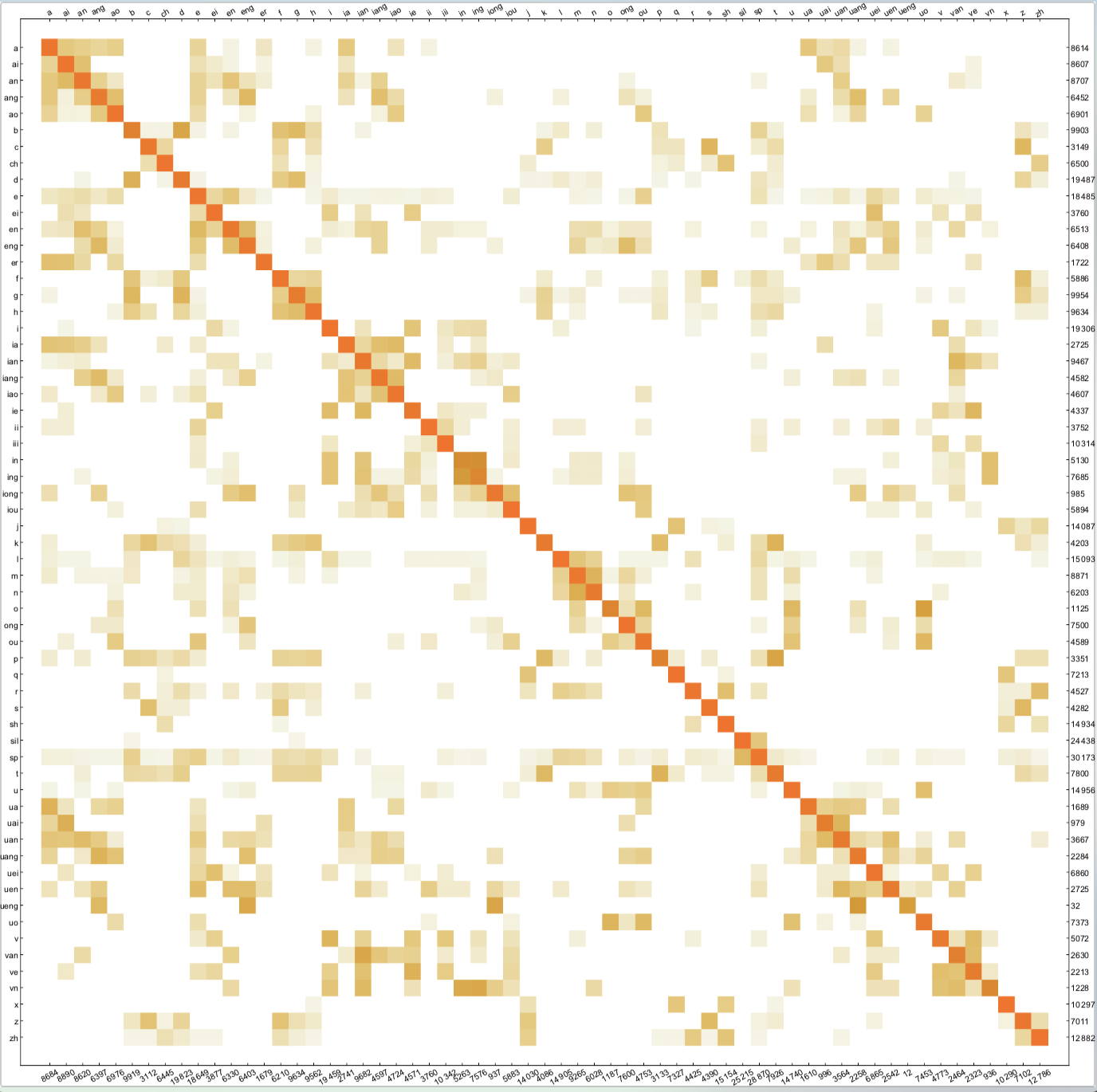
可视化混淆矩阵
在原始空间计算距离
即针对欧式距离最近的单元观察对应的所属类别是否相同来进行可视化
1 | data=Partition[Import["Unit2Vec_UnitVector.dat","Real32"],32]; |
1 | ReplaceiablePhoneDir="\\\\172.16.46.88\\xzhou\\project\\Yanping13k\\Unit2VecAddDur\\Unit2Vec_64_epochs50\\explain\\ReplaceiablePhone Unit2Vec_64_epochs50.wl"; |
使用Tensorboard
优点
- 可以交互
- 可以动态观察聚类情况
- 可以存储降维的结果
1 | import os |
PCA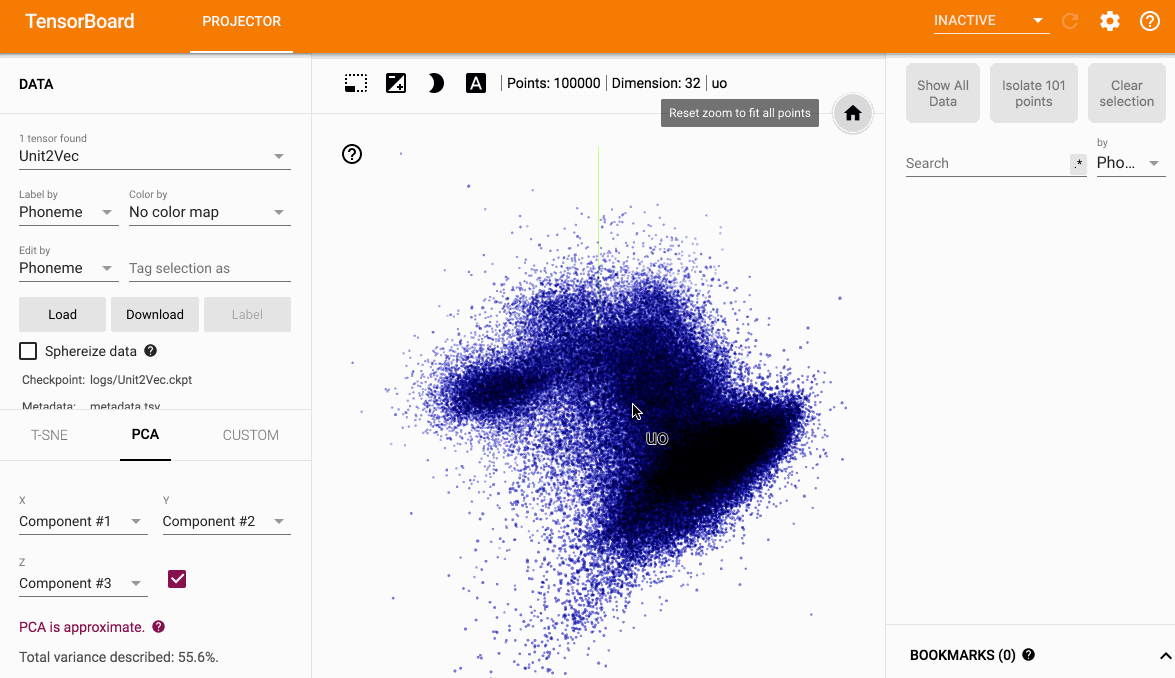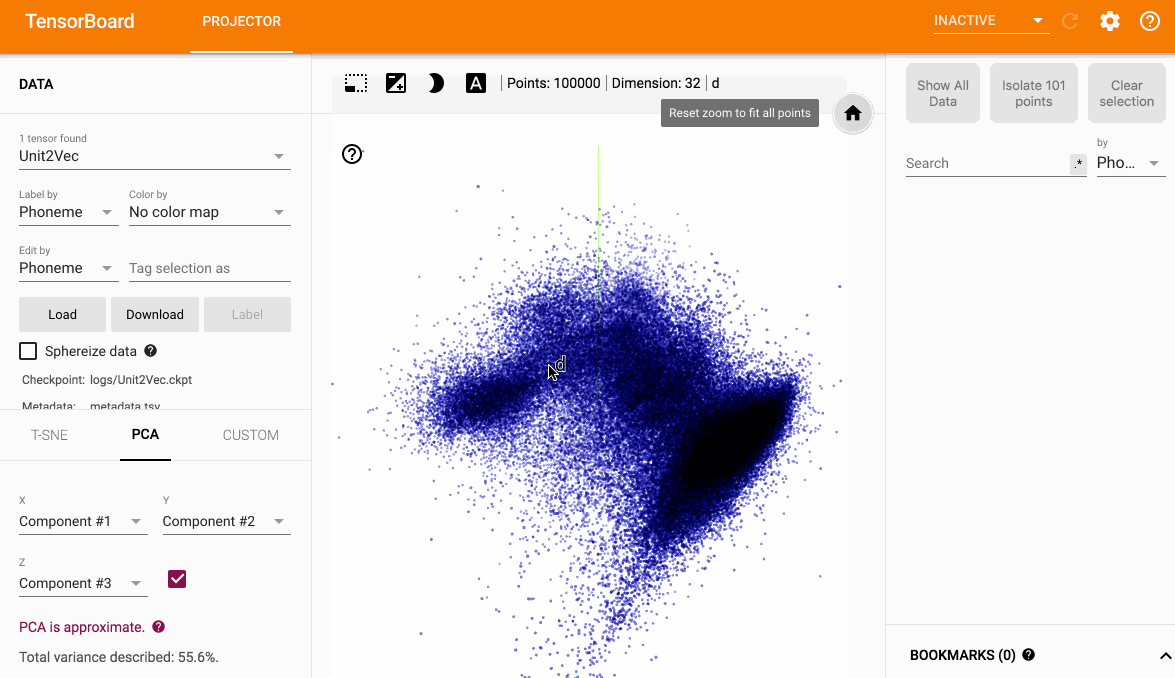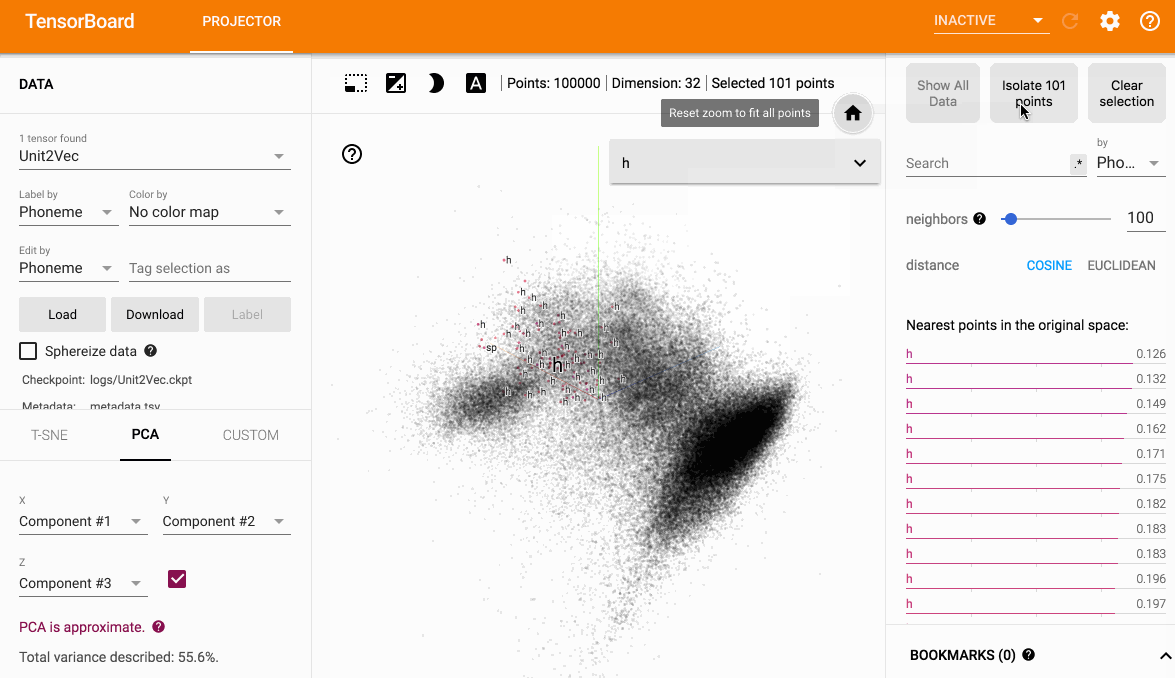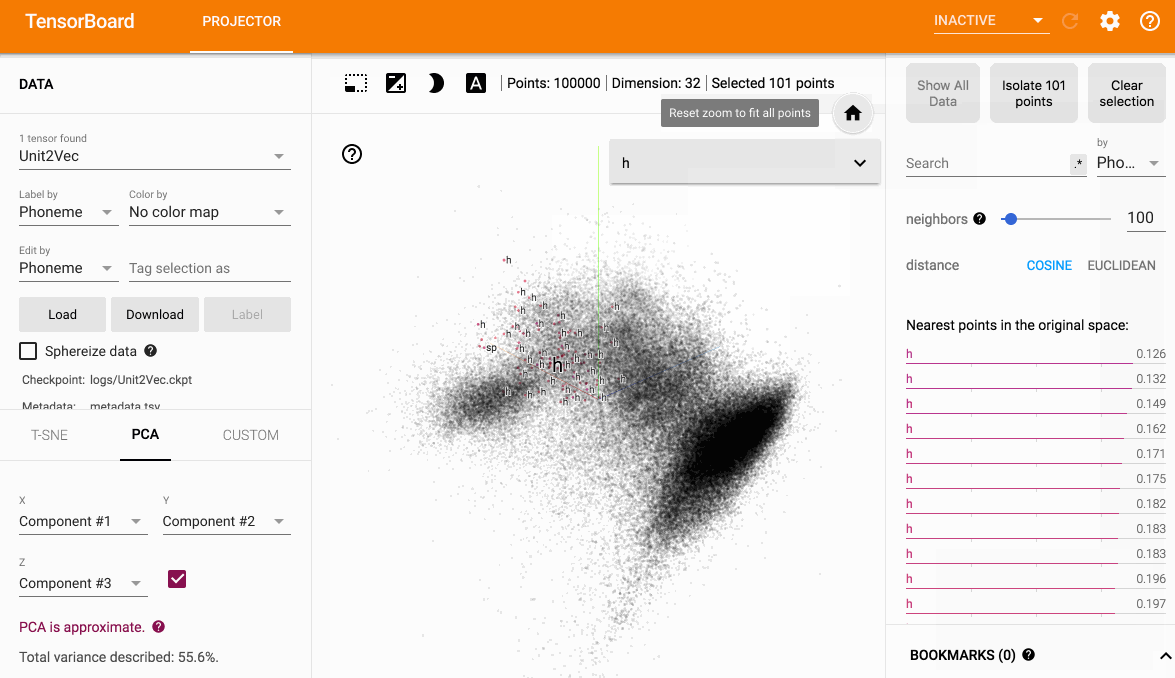
隔离查看相同音素对应的点(使用了正则表达式)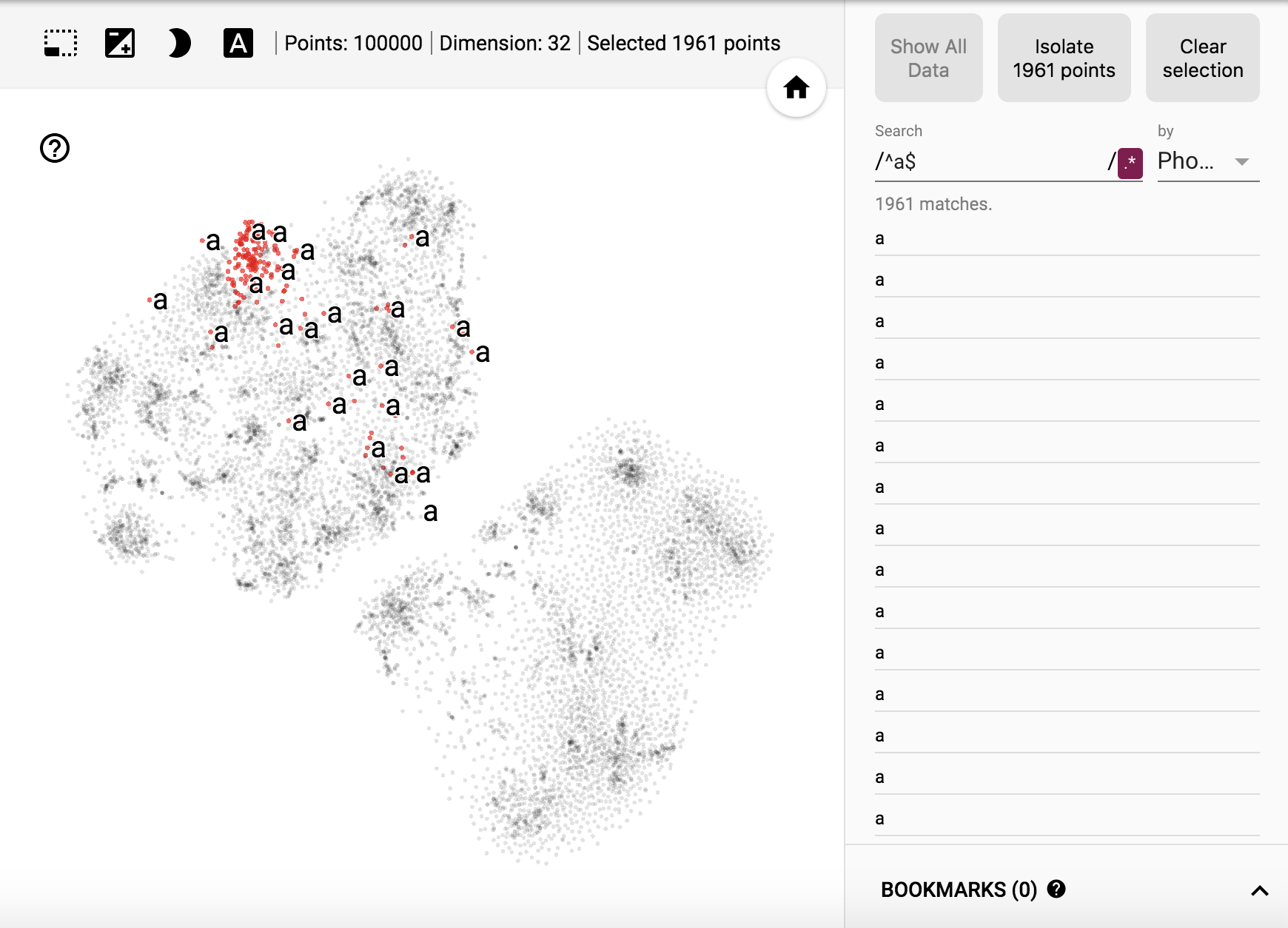
tSNE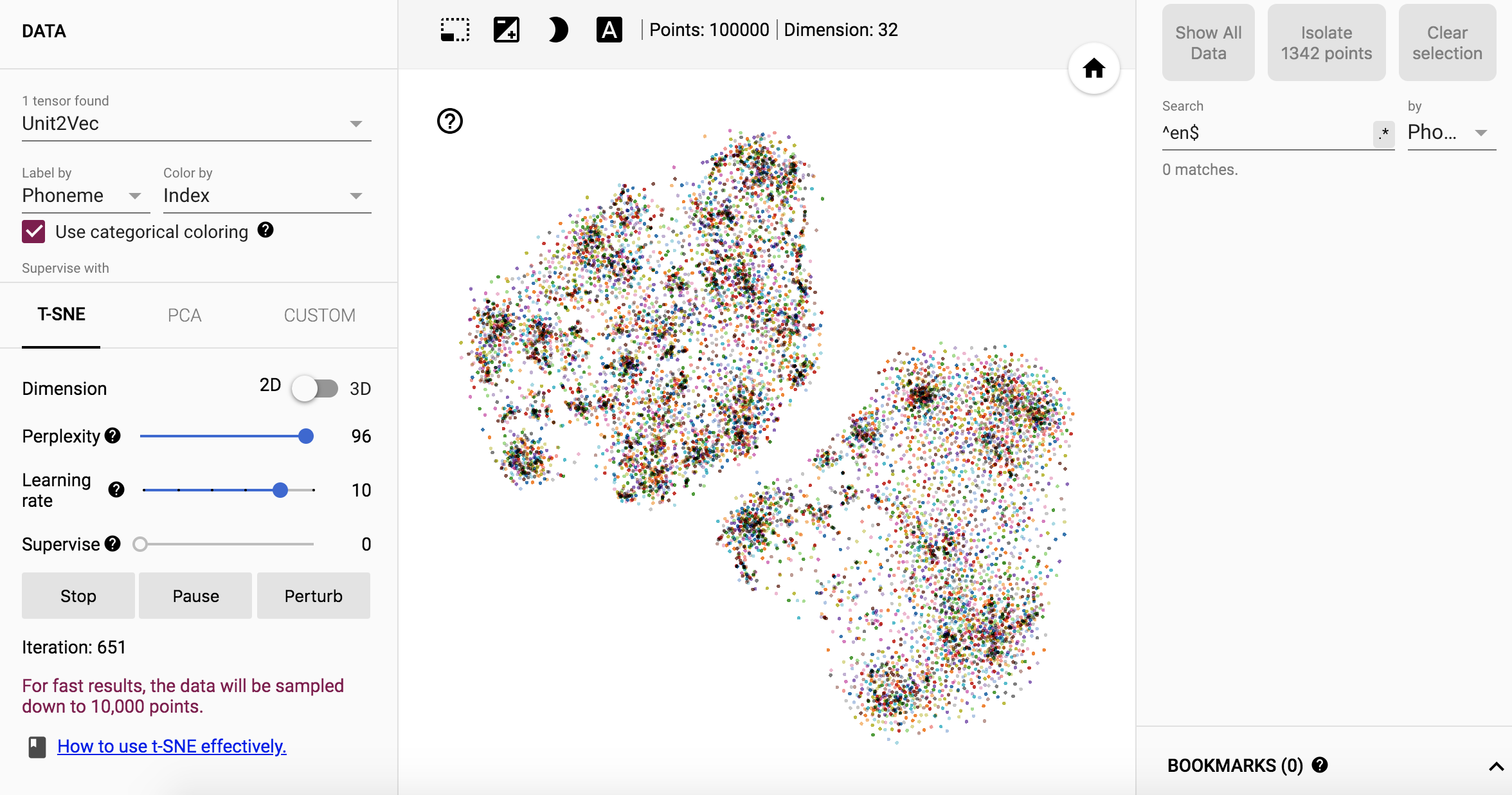
筛选点并可视化其他特征比如时长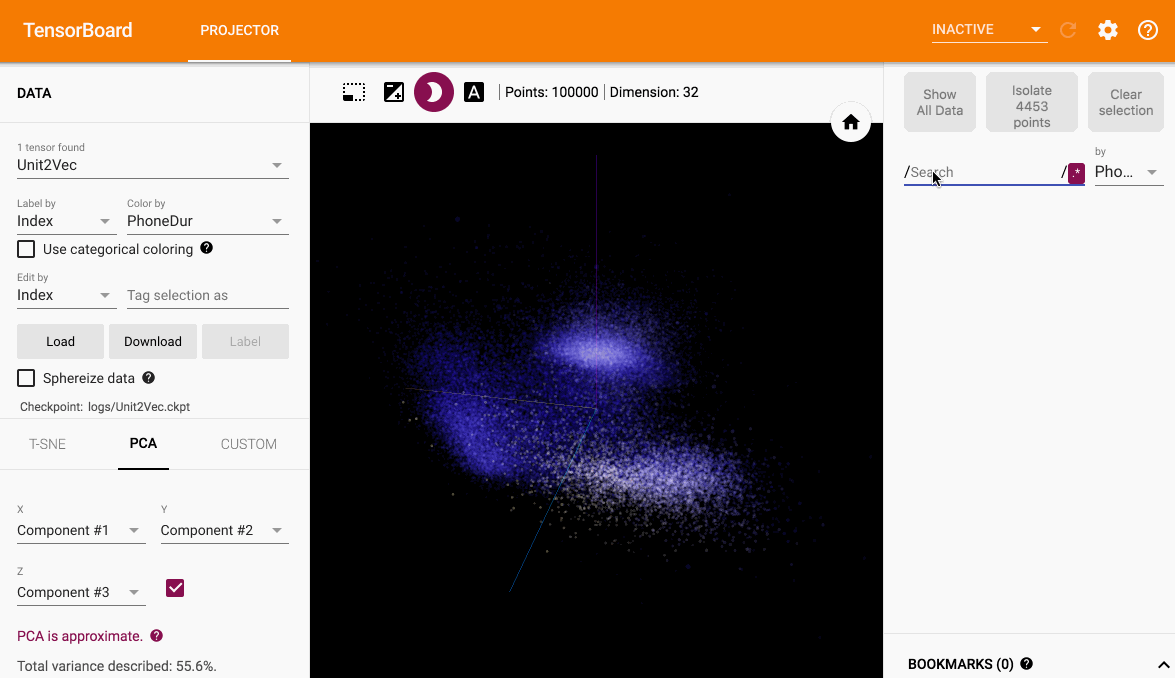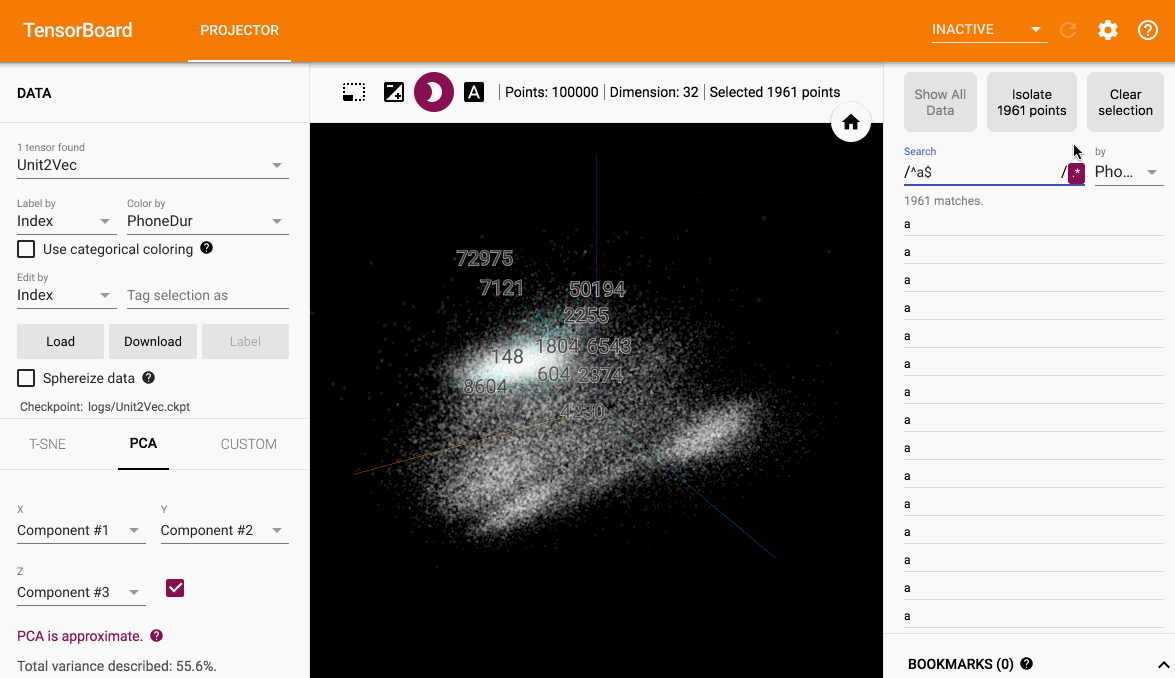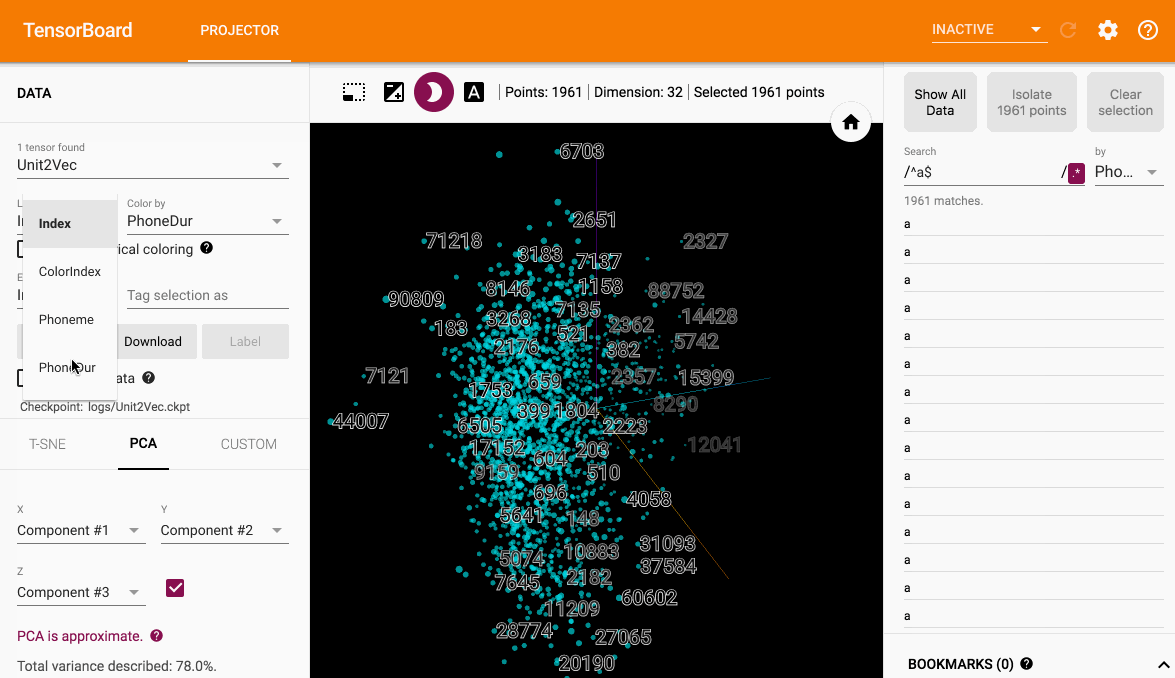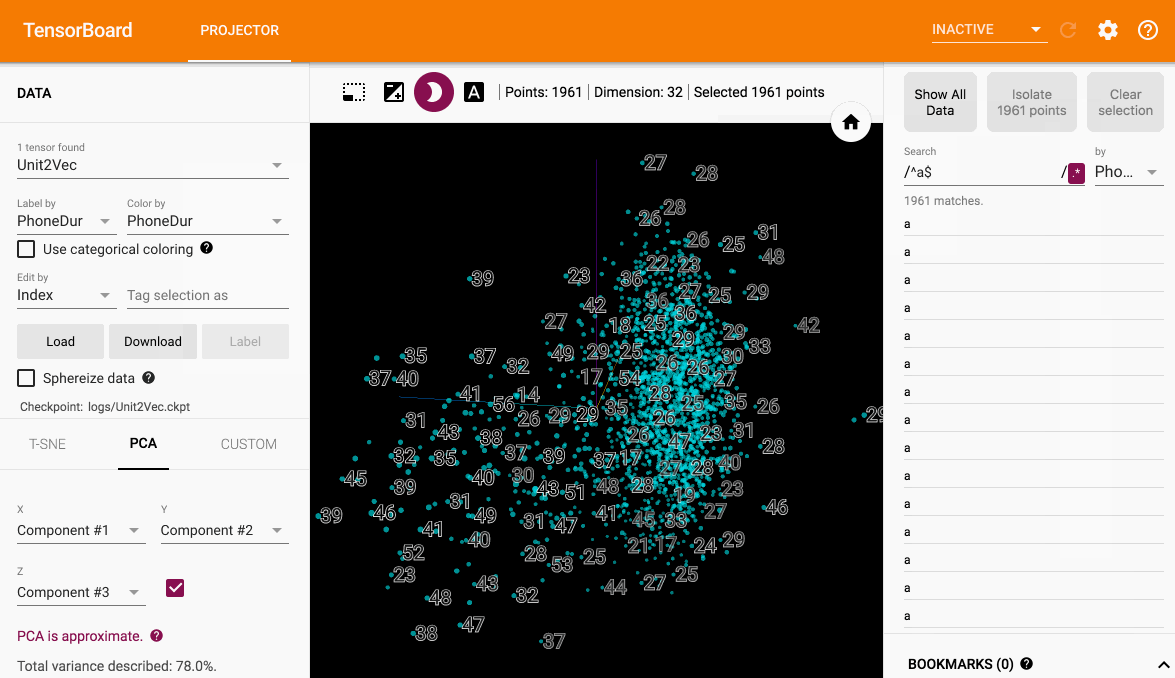
缺点在于
- 不能听音素对应的声音
- tSNE结果不如Mathematica好,而且mma也是完全不知道label信息去做降维的
- 不能在已经经过tSNE降维并显示所有音素类别的情况下,查看某个音素团的音素时长分布情况。也就是主图不能同时查看多种特征,自定义程度低
D3.js阶段
使用D3版本是5.5.0
因为我热爱可视化,所以决定学习D3.js,目前最流行的可视化库之一,不仅可以学习前端知识,Javascript还可以通过看别人的可视化项目培养艺术直觉
Github地址见我的Vis-UnitVector
在以下代码中,颜色渲染的方式和以前mathematica一样,只是背景色换成了黑色,更酷了是不是😁
之前Mathematica颜色是这样使用的, 就是第二个输出的61种颜色,现在把它转化为了十六进制形式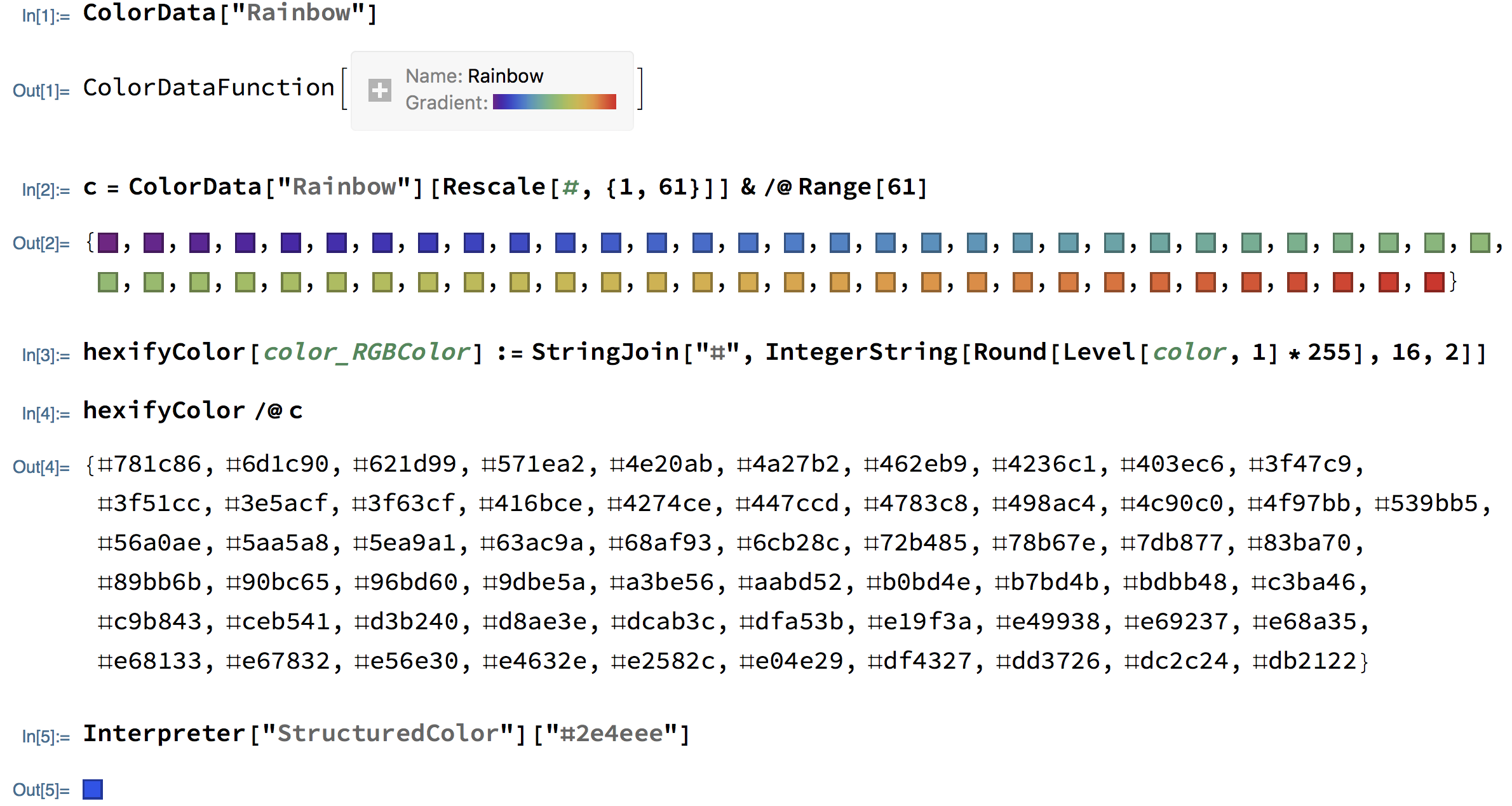
初期代码简单只能显示静态图1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
<html lang="en">
<head>
<meta charset="utf-8">
<title>Vis UnitVector</title>
<script type="text/javascript" src="d3/d3.js"></script>
<style type="text/css">
/* No style rules here yet */
</style>
</head>
<body>
<script type="text/javascript">
//Width and height
var w = 1170, h=680;
var dataset, cur_lab, selectQ = false; // a global
d3.json("Unit2Vec_tSNE.json").then(function(json)
{
dataset = json;
visualize();
});
function visualize()
{
//Create SVG element
var svg = d3.select("body")
.append("svg")
.attr("width", w)
.attr("height", h);
//创建背景用于触发点击事件(颜色复位)
svg.append("rect")
.attr("x", 0)
.attr("y", 0)
.attr("width", w)
.attr("height", h)
.attr("fill","black")
.on("click",function(d){
//触发背景点击事件,复位颜色的事件
d3.selectAll("circle")
.attr("fill", function(d) {
return color_map(d3.values(d)[0].lab);
});
//给文本传空字符串,因为当前点击的是背景而没点击任何点
d3.select("text").text("");
selectQ = false;
});
//添加文本显示当前点击的点对应的音素类别
svg.append("text")
.attr("x",100)
.attr("y",80)
.attr("font-size",50);
var min_max_x = d3.extent(dataset,function(d){return d3.values(d)[0].pos[0]});
var min_x = min_max_x[0];
var max_x = min_max_x[1];
var min_max_y = d3.extent(dataset,function(d){return d3.values(d)[0].pos[1]});
var min_y = min_max_y[0];
var max_y = min_max_y[1];
//创建映射点位置的比例尺
var xScale = d3.scaleLinear().domain([min_x,max_x]).range([0,w]);
var yScale = d3.scaleLinear().domain([min_y,max_y]).range([h,0]);
var phoneme = ["a", "ai", "an", "ang", "ao", "b", "c", "ch", "d", "e", "ei", "en", "eng", "er", "f", "g", "h", "i", "ia", "ian", "iang", "iao", "ie", "ii", "iii", "in", "ing", "iong", "iou", "j", "k", "l", "m", "n", "o", "ong", "ou", "p", "q", "r", "s", "sh", "sil", "sp", "t", "u", "ua", "uai", "uan", "uang", "uei", "uen", "ueng", "uo", "v", "van", "ve", "vn", "x", "z", "zh"]
var color = ["#781c86", "#6d1c90", "#621d99", "#571ea2", "#4e20ab", "#4a27b2","#462eb9", "#4236c1", "#403ec6", "#3f47c9", "#3f51cc", "#3e5acf","#3f63cf", "#416bce", "#4274ce", "#447ccd", "#4783c8", "#498ac4", "#4c90c0", "#4f97bb", "#539bb5", "#56a0ae", "#5aa5a8", "#5ea9a1", "#63ac9a", "#68af93", "#6cb28c", "#72b485", "#78b67e", "#7db877", "#83ba70", "#89bb6b", "#90bc65", "#96bd60", "#9dbe5a", "#a3be56", "#aabd52", "#b0bd4e", "#b7bd4b", "#bdbb48", "#c3ba46", "#c9b843", "#ceb541", "#d3b240", "#d8ae3e", "#dcab3c", "#dfa53b", "#e19f3a", "#e49938", "#e69237", "#e68a35", "#e68133", "#e67832", "#e56e30", "#e4632e", "#e2582c", "#e04e29", "#df4327", "#dd3726", "#dc2c24", "#db2122"]
//创建音素与对应颜色的序数比例尺
var color_map = d3.scaleOrdinal()
.domain(phoneme)
.range(color);
//创建一个包含比例尺的字典,可以将音素时长映射在[-2,2]内
var color_map_dict = new Array();
for (var i = 0; i < phoneme.length; i++) {
var min_max_dur = d3.extent(
dataset.filter(function(d)
{return d3.values(d)[0].lab == phoneme[i];}),
function(d){return d3.values(d)[0].dur});
color_map_dict[phoneme[i]] = d3.scaleLinear()
.domain([min_max_dur[0],min_max_dur[1]])
.range([-2,2]);
}
//设置点的相关事件属性
svg.selectAll("circle")
.data(dataset)
.enter()
.append("circle")
.attr("cx", function(d) {
return xScale(d3.values(d)[0].pos[0]);
})
.attr("cy", function(d) {
return yScale(d3.values(d)[0].pos[1]);
})
.attr("r", 3)
.attr("fill", function(d) {
return color_map(d3.values(d)[0].lab);
})
.call(d3.zoom().on("zoom",function(){
svg.attr("transform",d3.event.transform);
}))
.on("mouseover",function(d){
var info = d3.values(d)[0]
if(selectQ){
if(info.lab == cur_lab)
new Audio("wav_phone/"+info.name+".wav").play();
}
else
new Audio("wav_phone/"+info.name+".wav").play();
//给文本传当前鼠标滑过的音素名
d3.select("text")
.text(info.lab)
.attr("fill","white");
})
.on("click",function(d){
cur_lab = d3.values(d)[0].lab;
//给指定点上彩色,并根据每个单元时长不同上不一样的亮度
//时长越小越按,越大越亮
d3.selectAll("circle").filter(function(d) {
return d3.values(d)[0].lab == cur_lab;
})
.attr("fill", function(d) {
var info = d3.values(d)[0]
return d3.rgb(color_map(info.lab)).darker(color_map_dict[info.lab](info.dur));
})
//给其余点上灰色
d3.selectAll("circle").filter(function(d) {
return d3.values(d)[0].lab != cur_lab;
})
.attr("fill","grey");
selectQ = true;
})
;
}
</script>
</body>
</html>
整体图的展示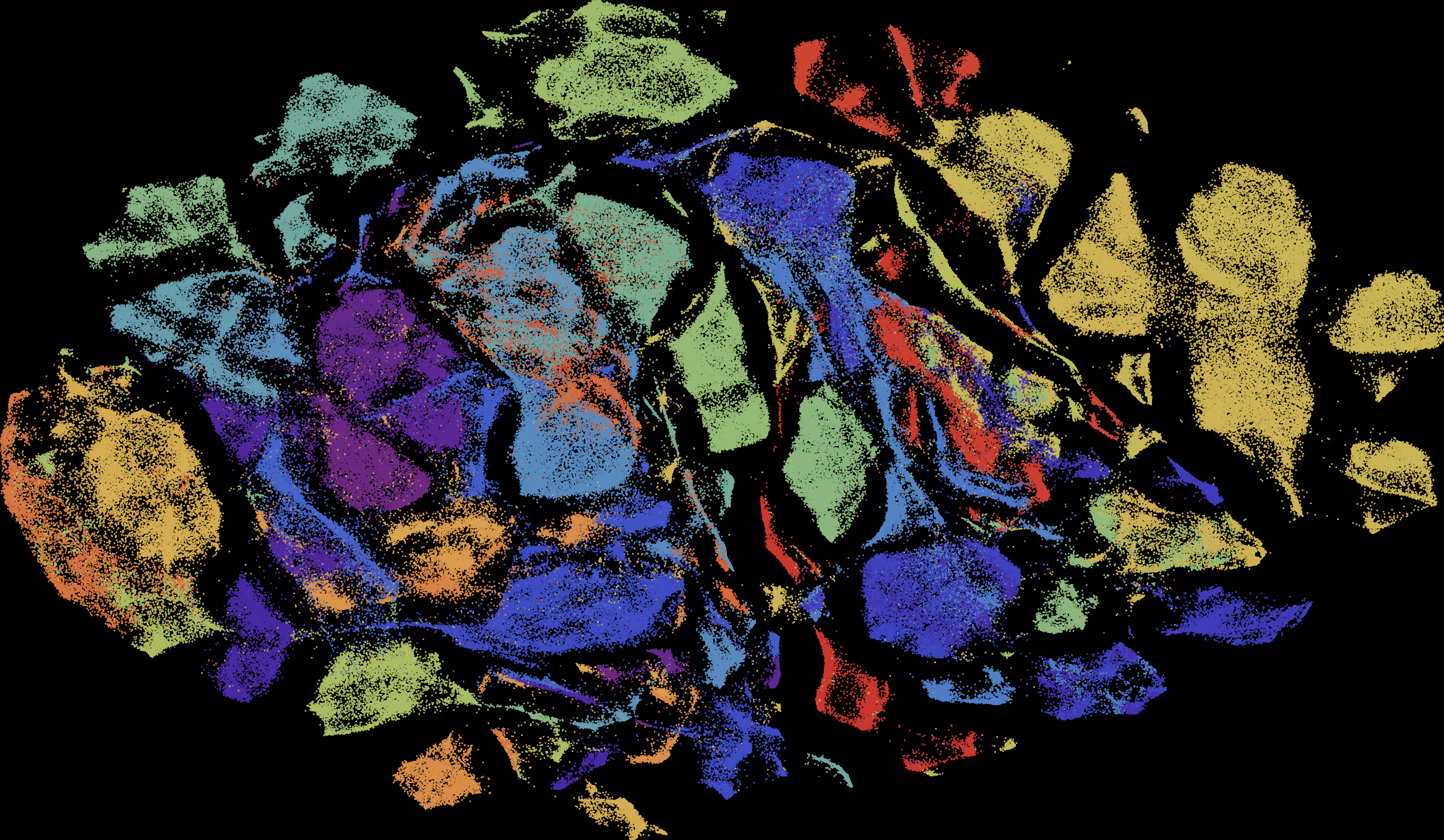
局部图的展示,选中某一个点之后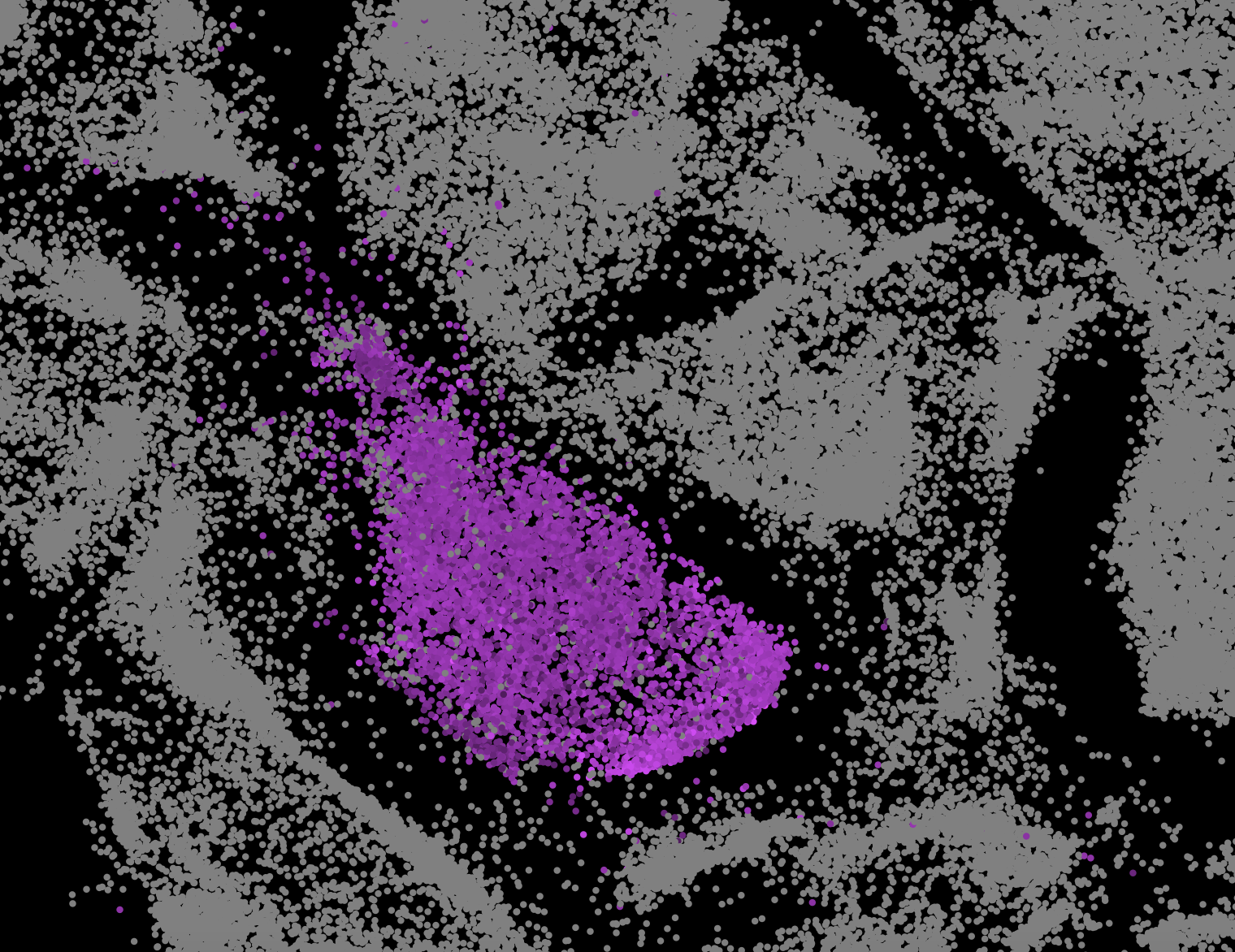
没对比没伤害,为什么D3画的图颜色这么好看捏~
继续探索…
比如离某音素最近的音素们是什么样的分布呢?
用Mathematica来探索
1 | SetDirectory[NotebookDirectory[]]; |
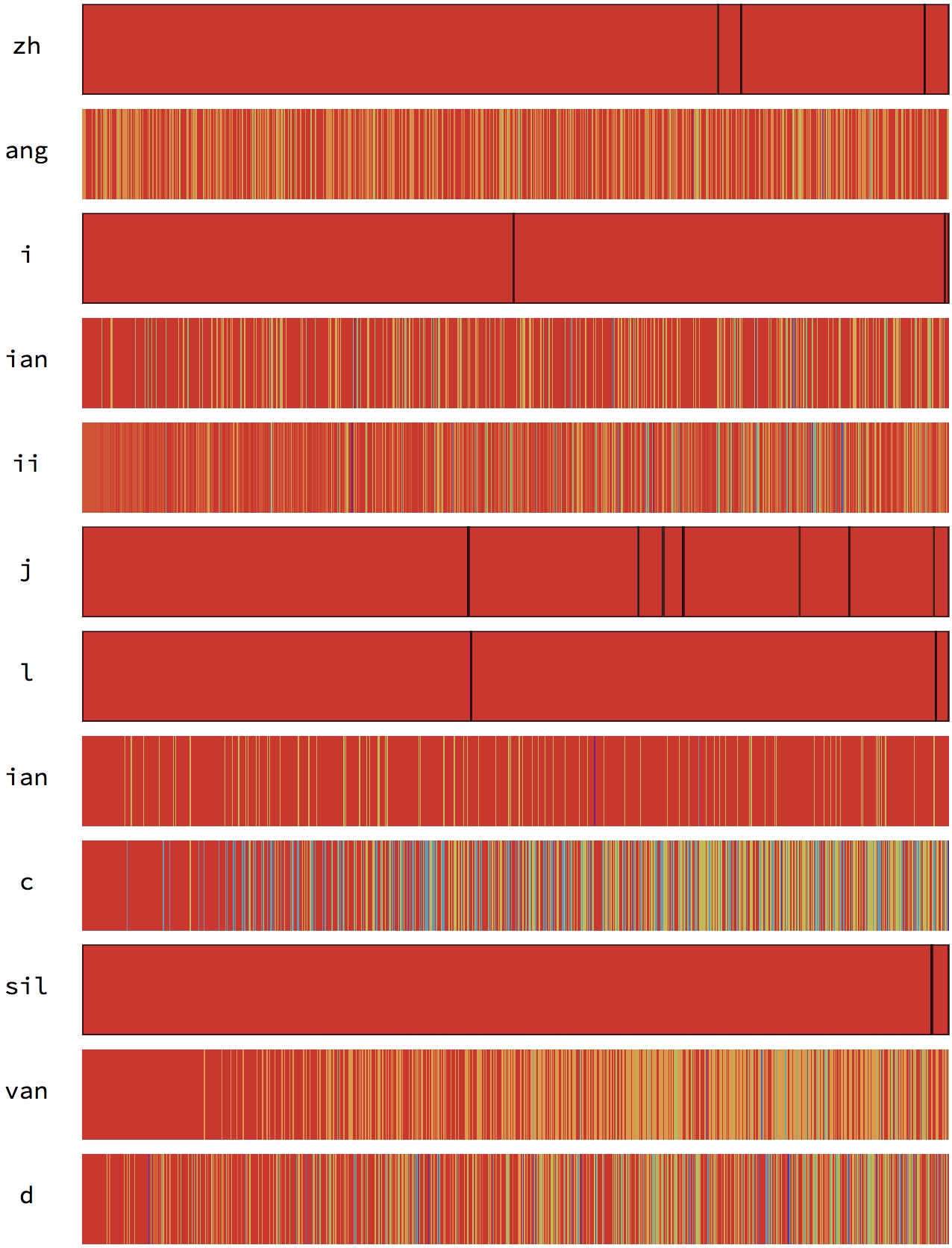
上色规则为:根据1000近邻内各个音素出现的次数从大到小排序,颜色按照这个次序渐进变化。
越靠近开头表示出现这个音素出现次数越多,可以看到偶尔一个音素的最近1000近邻中最多出现的音素竟然不是自己,这只能说聚类效果不好。因为这是随机从几十万的样本中抽出的12个例子,任意个体被抽中的概率是很低的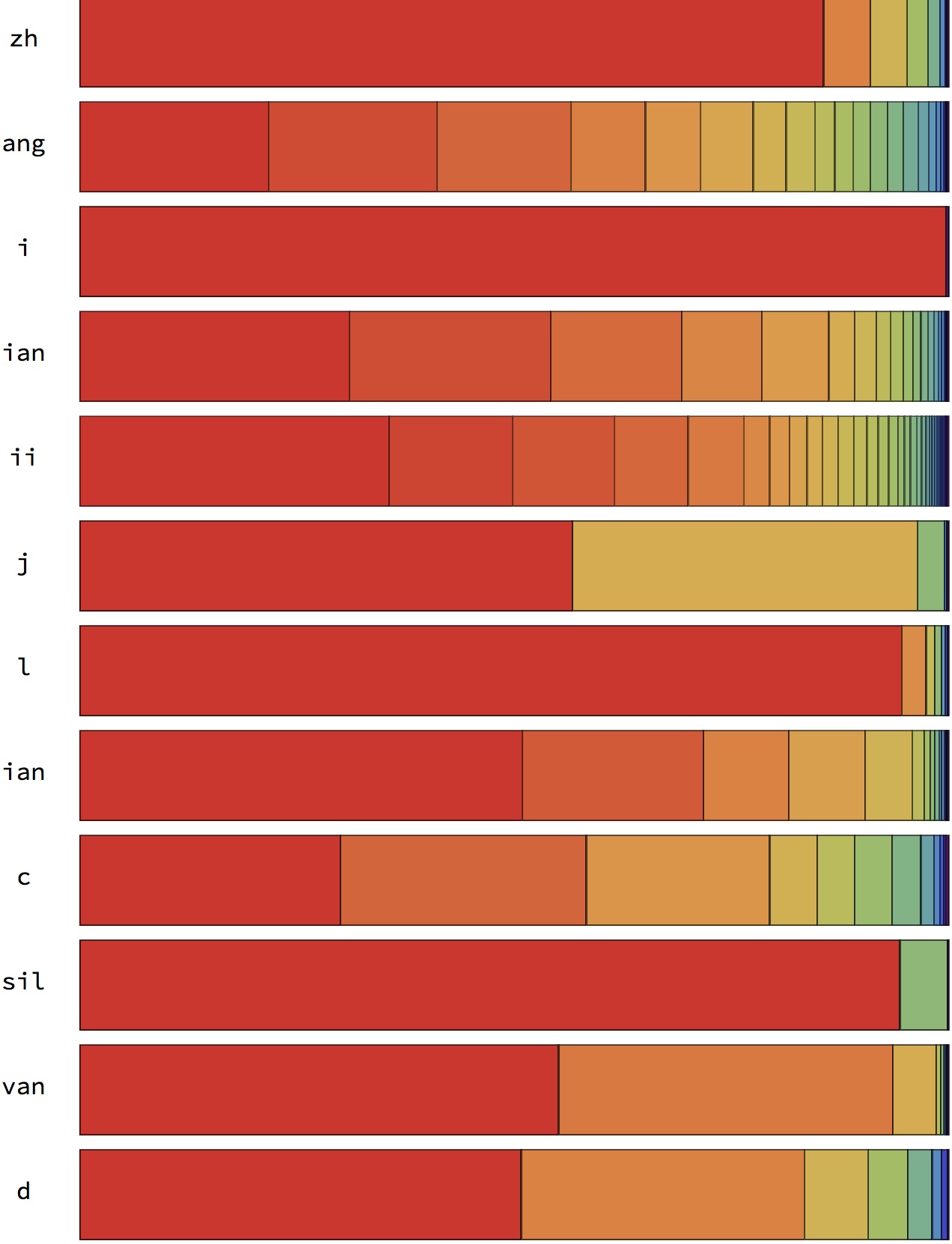
可以看到音素的最近邻之间也是距离相近的音素,出现最多的还是自己,其次是与它较相近的音素
但是仅宏观表示但是细节不够,不能体现第N近是哪个音素以及可视化最近邻分布的趋势
因此修改为1
2
3
4
5
6
7
8
9
10
11
12
13
14SeedRandom[23333];
Grid@Table[
Module[{nearps = phones[[asso[#]]] & /@ n[data[[i]], 1000], class,
col}, class = Keys@Sort@Counts[nearps];(*建立颜色映射*)
col = Association[Thread[class -> Rescale@Range[Length@class]]];
{phones[[i]],
BarChart[
Tooltip[Function[{val},
Style[val, ColorData["Rainbow", col[First@#]]]]@Length@#,
First@#] & /@ Split[nearps], BarSpacing -> {0, 0},
Frame -> False, Axes -> False, BarOrigin -> Left,
ChartLayout -> "Stacked", PlotRange -> {All, {.5, 1.5}},
AspectRatio -> 1/10, ImageSize -> 500]}], {i,
RandomSample[Range@Length[data], 12]}]
横轴是第1近邻、第2近邻直到第1000近邻。
上色规则为:颜色按照这个1000近邻中,音素所出现的的频率上色,出现越多的音素越偏红。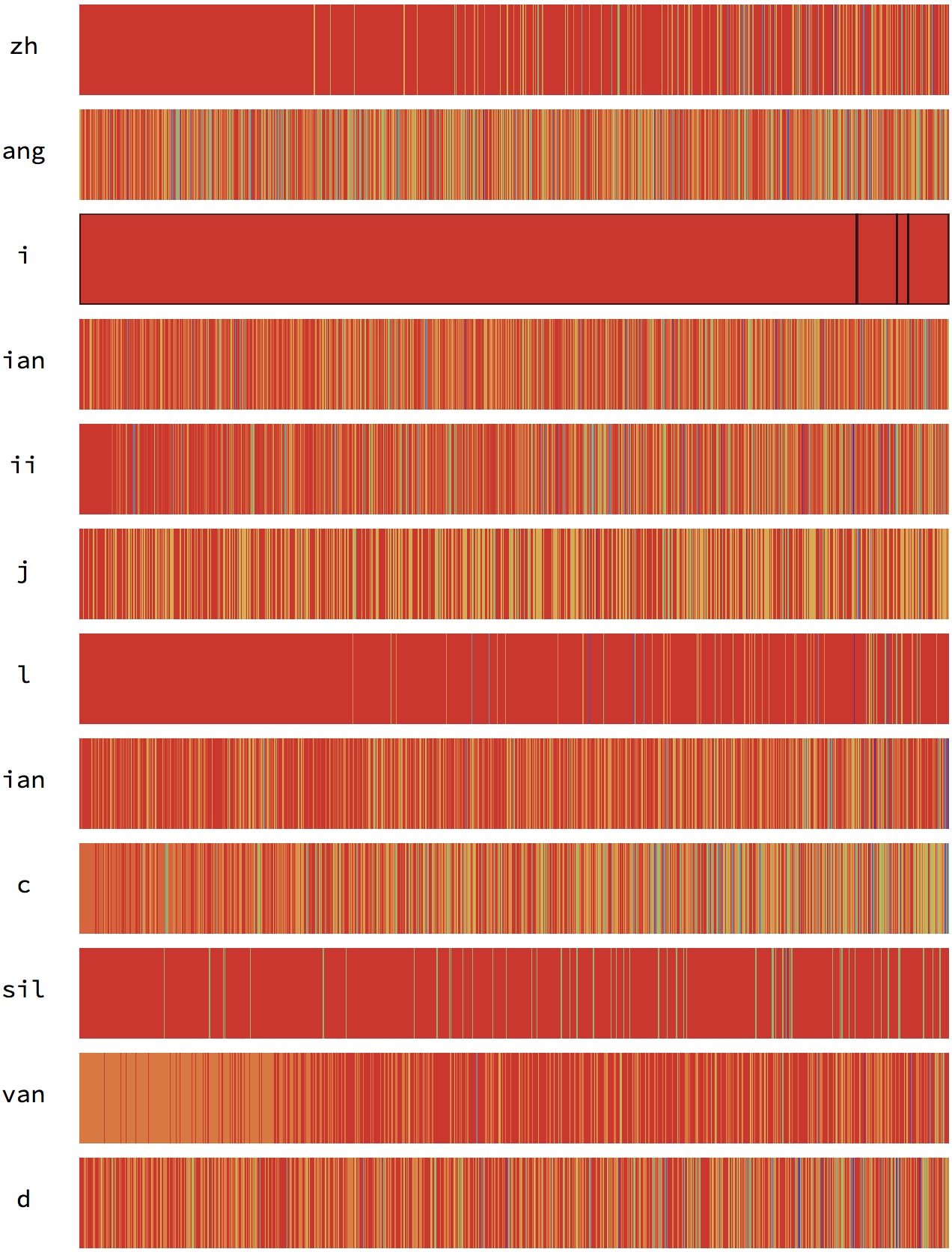
可以看到细节,混叠严重的话,最N近邻会频繁被其他音素打断
尝试给UnitVector更多信息的话,混叠可以减小