设置问题
没有图形化界面的机器导出图像
计算机是Linux服务器, 无图形化界面
链接How to save Image or Graphics in Terminal?
sudo apt-get install xvfb
xvfb-run wolfram
此时运行这个代码就正常了
1 | p=Graphics@Circle[]; |
状态栏显示时间
格式->选项设置(快捷键Ctrl+Shift+O),显示选项值选择全局偏好,搜索 EvaluationCompletionAction,将其设置为“ShowTiming”,笔记本下方的状态栏就会显示每次运行代码的消耗时间了。
当用到GPU并且执行wolframscript的语法是:CUDA_VISIBLE_DEVICES=1 xvfb-run wolframscript -file test.wl
基础知识
原子表达式不能替换头部
因为1是原子表达式,所以f不能替换掉它的头部1
2
3
4Apply[f, {{g[1], g[a]}, {g[2], g[b]}, {g[3], g[c]}}, {2}]
(* {{f[1], f[a]}, {f[2], f[b]}, {f[3], f[c]}} *)
Apply[f, {{1, g[a]}, {2, g[b]}, {3, g[c]}}, {2}]
(* {{1, f[a]}, {2, f[b]}, {3, f[c]}} *)
函数式指令
Gather将相同元素收集在一起1
2
3
4
5Gather[{{a, 1}, {b, 1}, {a, 2}, {d, 1}, {b, 3}}, First[#1] == First[#2] &]
(*or*)
GatherBy[{{a, 1}, {b, 1}, {a, 2}, {d, 1}, {b, 3}}, First]
(*{{{a, 1}, {a, 2}}, {{b, 1}, {b, 3}}, {{d, 1}}}*)
表格排版

新版
可以不用设置Partition,Grid组合起来用那么麻烦,因为Partition要考虑是怎么划分的Multicolumn[Range[50], 6]
旧版
Grid@Partition[Range[50], 6, 6, 1, ""]
尽量用Grid排版,而不是Row+Column
1 | Column[Row[#, " "] & /@ {{asa, b, c}, {x, y, z}, {adaasd, 1, 2}}] |
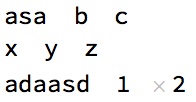
显得非常的不整齐
但是Grid就没问题 可以对齐1
Grid[{{asa, b, c}, {x, y, z}, {adaasd, 1, 2}}]

数学运算
求出最大/小元素的位置
求出最小元素的位置用Ordering[lis, 1];求出最大元素的位置用Ordering[lis, -1]
矩阵重复再拼接 类似numpy的tail函数
1 | ArrayFlatten[{ReplicateLayer[4]@mat}] // TraditionalForm |

数学证明
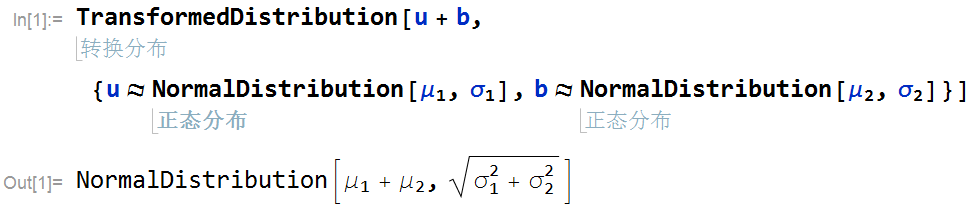
学习四元数
定义运算1
2
3
4
5
6
7quaternion[r_, x_, y_,
z_] := {{r, x, y, z}, {-x, r, -z, y}, {-y, z, r, -x}, {-z, -y, x,
r}};
quaternionQ[mat_?MatrixQ] :=
Simplify[Transpose[mat] + mat == 2 DiagonalMatrix[Diagonal@mat]];
fromquaternion[mat_?MatrixQ] :=
If[quaternionQ[mat], {1, i, j, k}.mat[[1]]];
这里使用的是矩阵形式定义四元数,来源于论文:
可以基于这个矩阵形式做如下运算:m=quaternion[3, 1, 0, 0].quaternion[0, 5, 1, -2];
得到新的四元数m(矩阵形式MatrixForm[m]),quaternionQ[m]输出真。
若得到普通形式需fromquaternion[m]
一般情况下两个四元数相乘是fromquaternion[
quaternion[Subscript[r, 1], Subscript[x, 1], Subscript[y, 1],
Subscript[z, 1]].quaternion[Subscript[r, 2], Subscript[x, 2],
Subscript[y, 2], Subscript[z, 2]]]
四元数的转置是fromquaternion@Transpose@quaternion[r, x, y, z]
四元数的乘法表:1
2
3
4TableForm[
Table[fromquaternion[
quaternion @@ UnitVector[4, a].quaternion @@ UnitVector[4, b]], {a,
4}, {b, 4}], TableHeadings -> {{1, i, j, k}, {1, i, j, k}}]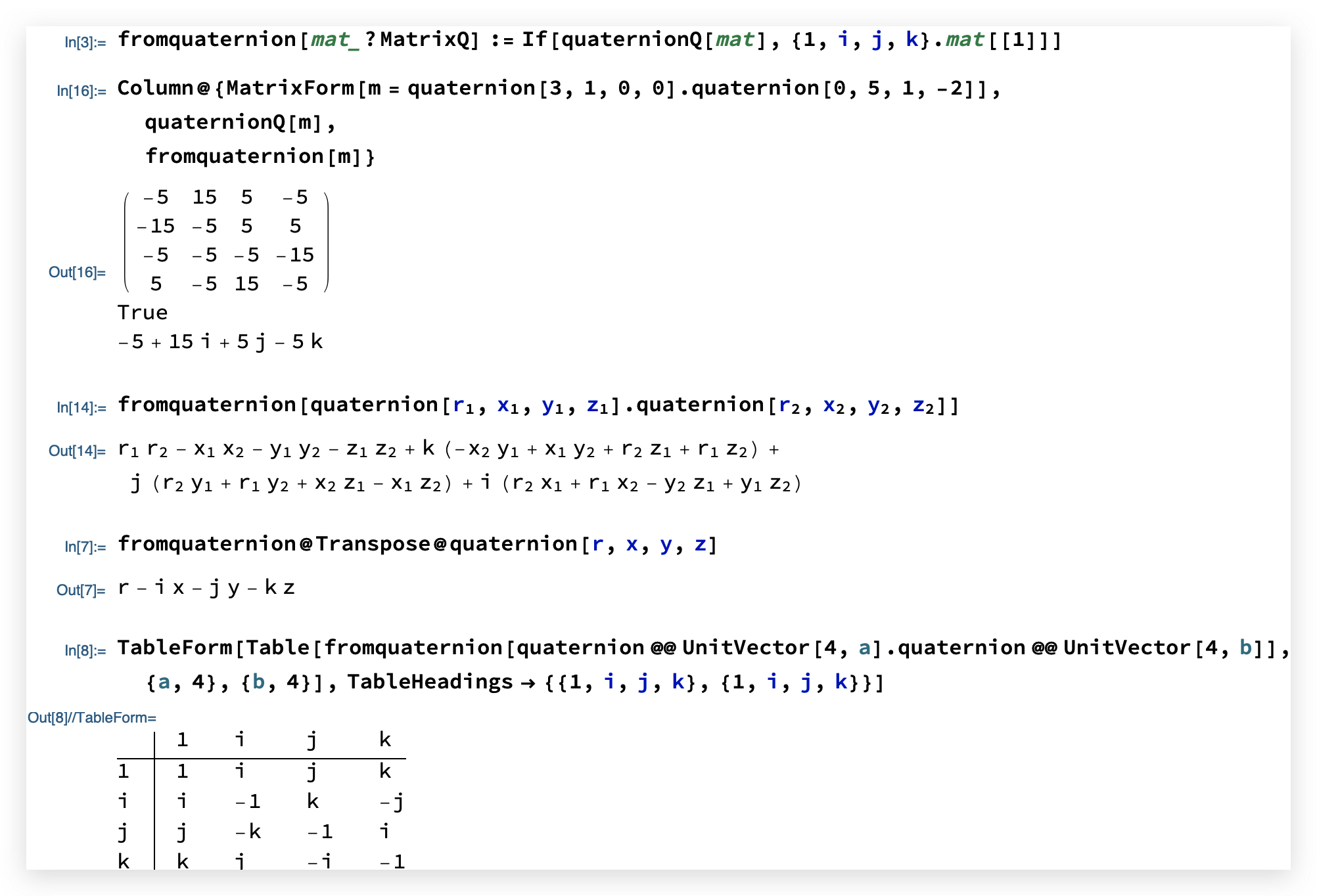
文件管理
列出文件夹下的文件
列出当前目录和子目录下所有后缀为nb的文件1
FileNames["*.nb","*",Infinity]
得到BaseName
1 | FileBaseName["C:\\Users\\xzhou\\Desktop\\test.gif"] |
保存mma表达式
1 | FilePrint @ Export["test.wl", Solve[x^2 + a x + 1 == 0, x]] |
可视化
CoordinateBoundingBoxArray
输入边界坐标,自动均匀填充边界内的点坐标1
2CoordinateBoundingBoxArray[{{3, -1}, {8, 2}}];
Graphics[Point[Flatten[%, 1]], Frame -> True]
在MatrixPlot和Graphics中插入文字
考虑Epilog选项和Inset图元
自动给曲线图打标签
1 | ListLinePlot[RandomReal[1, 26] -> CharacterRange["a", "z"]] |
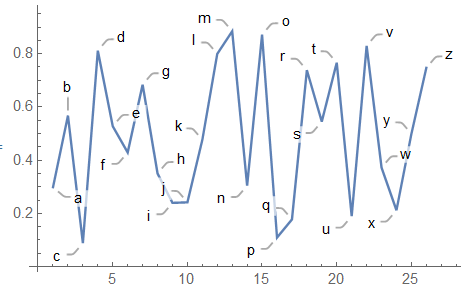
给特定点上标记信息
1 | color = {Red, Green, Blue}; |
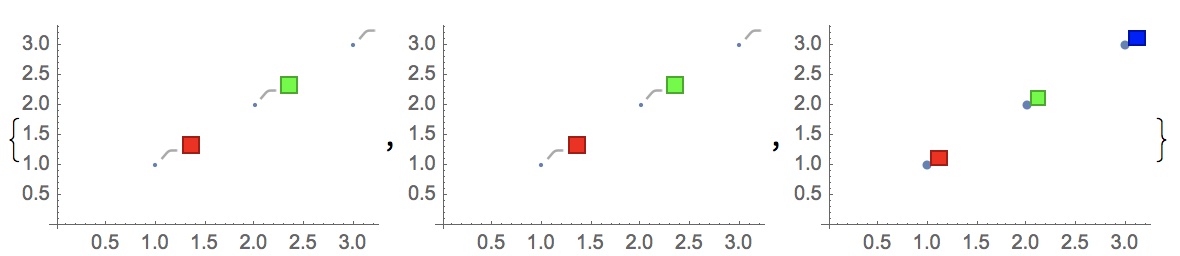
给特定点上特定颜色
ColorFunction
比如BarChart[{1, 2, 3}]是没颜色的BarChart[{1, 2, 3}, ColorFunction -> "Rainbow"]是有颜色的,颜色根据数值决定
大部分函数都可以用ColorFunction来指定颜色,不过ListPlot需要使用Joined选项才有效果
Style
但是注意到刚才的上色是根据数值计算得到的,那能不能根据数值在列表中的索引来上色呢?
默认选项是不能办到的,只能用Style1
2ListPlot[{Style[1, Red], Style[2, Green], Style[3, Blue]}]
BarChart[{Style[1, Red], Style[2, Green], Style[3, Blue]}]
其他
不过对于Raster可以另辟蹊径,因为它可以这么做1
2
3b = {{1, 2, 3}};
Graphics[Raster[b,
ColorFunction -> (ColorData["Rainbow", Rescale[#, MinMax[b]]] &)]]
当然它支持Association,不过只能画出对应label而不是颜色1
ListPlot[<|Red -> 1, Green -> 2, Blue -> 3|>]
音频函数
语音合成
Speak可以让Mma说话,SpokenString可以显示说话的内容
让Audio自动播放声音:
最后的参数”Play”可以换成Pause Stop之类的1
2au = ExampleData[{"Sound", "Violin"}];
Audio`Internals`Execute[ Audio`Internals`GetAudioManager[ Audio`AudioInformation[au, "AudioID"]], "Play"]
得到Audio文件此时的播放位置
1 | id =Audio`AudioInformation[song, "AudioID"];mngr = Audio`Internals`GetAudioManager[id];Dynamic@Audio`AudioDump`getGUIInfo[mngr, "AudioPosition"] |
计算音频的能量
1 | a = ExampleData[{"Sound", "Violin"}]; AudioMeasurements[a, "RMSAmplitude"] |
常用替换
Audio Sound
1 | (*Audio->Sound*) |
List Association
1 | (*List->Association*) |
替换
1 | (*函数式 {1->2,2->3} -> {{1,2},{2,3}}*) |
Dataset
深入、退出运算符
值得注意的是TakeLargestBy是深入运算符,TakeLargest是退出运算符。
- 在后面的运算符应用到更深一层之前,“深入”运算符被应用到原始数据集相应的部分. 深入运算符的特点是在作用于某一层时,它们不会改变数据更深层次的结构. 这确保后面的运算符操作时,子表达式的结构和原始数据集的相应层次是一样的. 最简单的深入运算符是 All,它选取某个给定层的所有部分,因此不会改变该层数据的结构
- 在所有随后的运算符完成对深层数据的操作后,“退出”运算符被应用.因此
dataset[f,g]是Query[f, g] // Normal,也就是Map[g] /* f.深入运算符对应于原始数据的层,而退出运算符对应于结果的层. 和深入运算符不同,退出运算符不必保持所操作数据的结构. 如果一个运算符没有被明确指定为深入运算符,假定其为退出运算符
data[SortBy[#x - #y &], Total, #^2 &]是深入、退出1、退出2运算符,因此先应用深入运算符,再应用#^2 &,再应用Total
数据分析或处理
利用SQL语法查询数据
sales = SemanticImport["ExampleData/RetailSales.tsv"]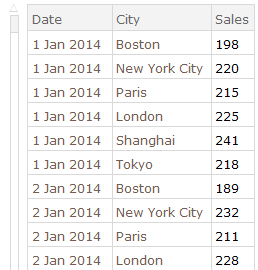
sales[All, "Sales"]得到Sales列的所有数据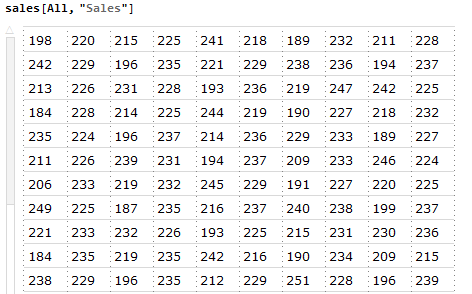
因为All是深入运算符,可以安全的更换为其他深入运算符,如sales[Mean, "Sales"] // N
这时候如果想再针对月份和星期几排序可以这样:1
2sales[GroupBy[DateValue[#Date, "Month"] &],
GroupBy[DateValue[#Date, "DayName"] &], Mean, "Sales"]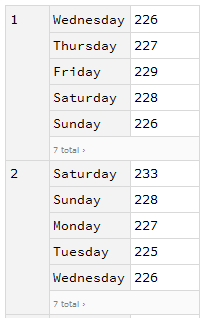
聚类

ClusteringComponents的第二个参数意思是聚类个数为3类,第三个参数将第一层数据视为一个样本
归一化数据
对数据(矩阵)做归一化,数据每行是一个样本,每一列是一个特征
均值文件存储的也是矩阵。第一行是最小值,第二行是最大值
若只对矩阵第一维归一化1
data1[[All, 1]] = (data1[[All, 1]] - meanInput[[1, 1]])/(meanInput[[2, 1]] - meanInput[[1, 1]]);
若对矩阵的每一维做归一化1
mat = (# - meanOutput[[1]])/meanOutput[[2]] & /@ mat;
实用小功能
美化输出
GeneralUtilities`PrettyForm可以美化输出
导出矢量图
SVG和wmf文件可以输出矢量图,wmf适合visio
将PDF中的段落变成一行,方便谷歌翻译使用
先复制段落再粘贴进mma执行以下代码1
StringDelete[text, "\n"] // CopyToClipboard
当然CopyToClipboard可以直接拷贝数据至剪贴板,也对复制图片是极好的
导出数学公式至Stack Exchange
例如http://math.stackexchange.com
公式选择复制为Latex格式 然后在前后加上$就行了1
$c=\sqrt{a^2-2 a b \cos (\theta )+b^2}$
导出含有Alpha通道的图片
1 | img//Binarize//ColorReplace[#,Black->Red]& |
快速显示📂各种文件后缀的总大小
1 | fs=Select[FileNames["*","F:\\source",Infinity],FileType@#==File&]; |
加密📂所有文件
1 | files = Select[ |
导入导出
导入
导入lst文件(每行均为数字构成)Import[filename,"List"]
导入lst文件(每行均为字符串构成)Import[filename,"Lines"]
导入纯文本构成的矩阵 Import[filename,"Table"]
导入浮点数二进制文件 BinaryReadList[filename,"Real32"]
如果一些tsv文件导入乱码比如使用Import[filename,"Table"可以尝试1
2
3Import["/Users/xzhou/python/nvshens/Girls.lst", "TSV"]
(*Or*)
StringSplit[StringSplit[#, "\n"], "\t"] & @ Import[filename,"Text",Character->"UTF8"]
文件流控制
以二进制文件形式导入
Import不会引入新的流,简单但是灵活性低1
2Import["test.exe", "Byte"] // Length
Streams[] // Length (*2,证明只有输出流stdout和错误流stderr*)
OpenRead 如果用完关闭流也不会引入新的流,稍复杂但是灵活性高1
2
3
4
5
6
7file = OpenRead["test.exe",
BinaryFormat -> True];
Length@Reap[
While[(tempRecord = BinaryRead[file]) =!= EndOfFile,
Sow@tempRecord]][[2, 1]]
Close[file];
Streams[] // Length (*2,证明只有输出流stdout和错误流stderr*)
不管是BinaryReadList还是BinaryRead都会改变流指针的位置:
Mathemtica向文件追加二进制数据
1 | file = "test.dat"; |
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 15, 16, 17, 18, 19, 20, 21, \
22, 23, 24, 25, 26, 27, 28, 29, 30}
继续追加1
2
3
4
5str = OpenAppend[file, BinaryFormat -> True];
BinaryWrite[str, Range[5], "Real32"];
BinaryWrite[str, Range[10, 15], "Real32"];
Close[str];
BinaryReadList[file, "Real32"]
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 15, 16, 17, 18, 19, 20, 21, \
22, 23, 24, 25, 26, 27, 28, 29, 30, 1, 2, 3, 4, 5, 10, 11, 12, 13, \
14, 15}
不导出也查看导出的效果
比如ExportString[{1, {1, 2, 3}}, "Table"]输出的效果就是Export["test.txt",{1, {1, 2, 3}}, "Table"]打开后的效果
单元 笔记本
在单元中启用动态1
TextCell[Dynamic[ Refresh[DateString[], UpdateInterval -> 1]], "Subsection"]
时序数据
TimeSeries的头部依然是TemporalData1
2
3
4v = {2, 1, 6, 5, 7, 4};
t = {1, 2, 5, 10, 12, 15};
ts = TimeSeries[v, {t}]
Head[ts](* TemporalData *)
两条路径使用 TemporalData而不是TimeSeries1
2
3
4s1 = {2, 1, 6, 5, 7, 4};
s2 = {4, 7, 5, 6, 1, 2};
t = {1, 2, 5, 10, 12, 15};
td = TemporalData[{s1, s2}, {t}]
Differences和Accumulate可以用于 TemporalData,但是要注意采样是否均匀的问题
打开数据库文件(SQLite)
1 | Needs["DatabaseLink`"]; |