MXNet基本指南
打开mxnet
source activate gluon # 注意Windows下不需要 source
退出环境source deactivateGPU版本进入环境后如果用指定的卡可以
CUDA_VISIBLE_DEVICES=2 python,这样数据只能分配在一个GPU上- 可以尝试将数据全部放进内存,如果是不规则数据集,numpy处理不了可以用python自带的数组处理
CUDA_VISIBLE_DEVICES=2 jupyter notebook,进入jupyter后再导入mxnet,如果使用GPU训练,也只训练在一块卡上- 升级
pip install mxnet --upgrade,安装每日更新版本可以加上--pre参数。pip search mxnet可以看到还有许多mxnet版本,比如mxnet-cu75、mxnet-cu80、mxnet-cu90等 - 可以不让MXNet占用过多显存,设置保留的百分数
export MXNET_GPU_MEM_POOL_RESERVE=5
MXNet如何处理训练模式和测试模式
Gluon:若在调研网络时被with autograd.record()包裹,那么这时Gluon是训练模式。如果没有则是测试模式。可以参见在论坛的帖子得到一些证明
MNNet的Module加载模型并运算默认是训练模式,测试模式需要指明mod.forward(Batch([x]),is_train=False),MNNet的新版加载函数(v1.2.1以上)加载模型方式(mx.gluon.nn.SymbolBlock.imports)并运算默认是测试模式
C++:默认是测试模式
模型的导入导出
在1.3.0版本之前,我对于Hybrid模型采用export导出,LSTM这种无法Hybrid化的模型采用save_params的方式。
但是save_params方式一方面无法载入C++,一方面每次Python导入模型都要重新定义网络结构,很麻烦
今天才知道一个v1.2.1之后引入了有趣的导入函数mx.gluon.nn.SymbolBlock.imports,模型采用export导出后(1.3.0版本之后rnn、lstm等也可以顺利导出了),就有params和json两个文件,分别存储权重和网络结构,即可预测了
下面这个例子显示的结果一样,但是更简单便捷。
DNN的输入: (batch, 535) 输出:(batch, 43)
LSTM的输入:(duration, batch, 535) 输出:(duration, batch, 43)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21import mxnet as mx
from mxnet import gluon
from collections import namedtuple
data= mx.random.uniform(shape=(3,535))
##### New way #####
# import LSTM model
net = gluon.nn.SymbolBlock.imports('LSTM-symbol.json', ['data'], param_file='LSTM-0000.params', ctx=mx.cpu())
print net(mx.nd.zeros(shape=(3,1,535))) #100 can be other number
# import DNN model
net = gluon.nn.SymbolBlock.imports('DNN-symbol.json', ['data'], param_file='DNN-0000.params', ctx=mx.cpu())
print net(data) #100 can be other number
##### Old way #####
# import DNN model
sym = mx.symbol.load('DNN-symbol.json')
mod=mx.mod.Module(symbol=sym)
mod.bind(data_shapes=[('data',(1,535))])
mod.load_params('DNN-0000.params')
Batch=namedtuple('Batch',['data'])
mod.forward(Batch([data]),is_train=False)
print mod.get_outputs()[0]
数据操作
expand_dims和flatten
data是(3,4)的形状,如果想变成(3,1,4),可以reshape,但是更好的办法是.expand_dims(axis=1),再变回去也只要.flatten()就行,因为flatten函数会将输入的(d1,d2,d3…)维度变为(d1,d2d3…)
nd.concatenate(被弃用,改为nd.concat)
1 | print img_list[0].shape #(1L, 3L, 64L, 64L) 每个都是这样的形状 |
nd.concatenate([history,temp],axis=1)或者nd.concat(history,temp,dim=1)对应F.concat(history, temp, dim=1)
计算L2Loss
1 | import mxnet as mx |
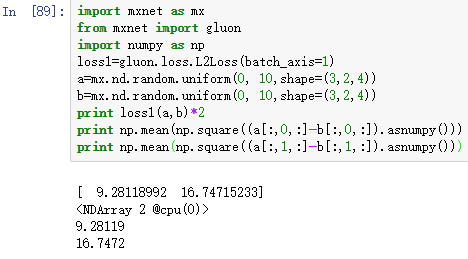
网络
RNN
1 | layer = mx.gluon.rnn.RNN(100, 3) |
Embedding
1 | net.weight.data().asnumpy() |
mask-RNN
重要的SequenceMask函数
第二个参数表示这个mini-batch内几个样本是真实的,这里代表两个真实1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25x = mx.nd.array([[[ 1., 2., 3.],
[ 4., 5., 6.]],
[[ 7., 8., 9.],
[ 10., 11., 12.]],
[[ 13., 14., 15.],
[ 16., 17., 18.]]])
#x.shape=(3L,2L,3L)
res=mx.nd.SequenceMask(x,mx.nd.array([2,1]), use_sequence_length=True)
print res
#表明第一个batch保留两个time-stseps,第二个batch保留1个time-stsep
# 得到
# [[ 1. 2. 3.]
# [ 4. 5. 6.]]
# [[ 7. 8. 9.]
# [ 0. 0. 0.]]
# [[ 0. 0. 0.]
# [ 0. 0. 0.]]]
#这样的话 res[:,0,:]取出的就是第一个batch加了mask的结果
# [[ 1. 2. 3.]
# [ 7. 8. 9.]
# [ 0. 0. 0.]]
# res[:,1,:]取出的就是第2个batch加了mask的结果
# [[ 4. 5. 6.]
# [ 0. 0. 0.]
# [ 0. 0. 0.]]
首先解决带mask的loss
1 | # -*- coding: utf-8 -*- |
网络可视化
sym.list_outputs()
列出一个模型输出端口的名字
sym.list_arguments()
列出一个模型的输入端口的名字以及权重和偏置的名字
sym.tojson()
可以打印出网络结构
mod.get_outputs()
列出前馈的输出
显示网络结构 viz.plot_network
直接显示网络结构mx.viz.plot_network(symbol=sym)
1 | graph = Import["ExampleData/mxnet_example2.json", {"MXNet", "NodeGraphPlot"}] |
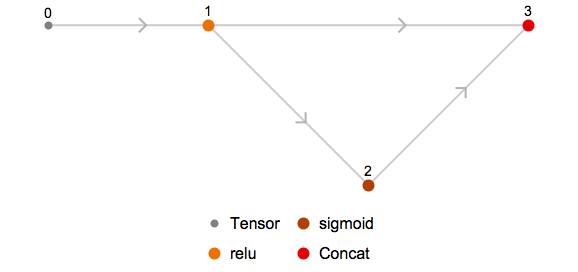
1 | graph = Import["ExampleData/mxnet_example2.json", {"MXNet", "NodeGraph"}] |
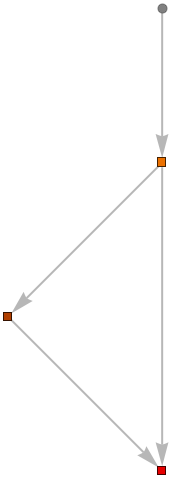
MXNet高阶应用
MXNet与C++联动
步骤
- 在python中训练MXNet模型
- 在python中导入模型,并进行预测
- 在C++中导入模型(在小例子上进行验证两个接口结果一致)
- 在C++项目中使用模型
配置C++平台
- 在C++/常规中添加“附加包含目录”,即工作目录,方便定位c_predict_api.h的位置。如果能成功#include的话,不设置也行
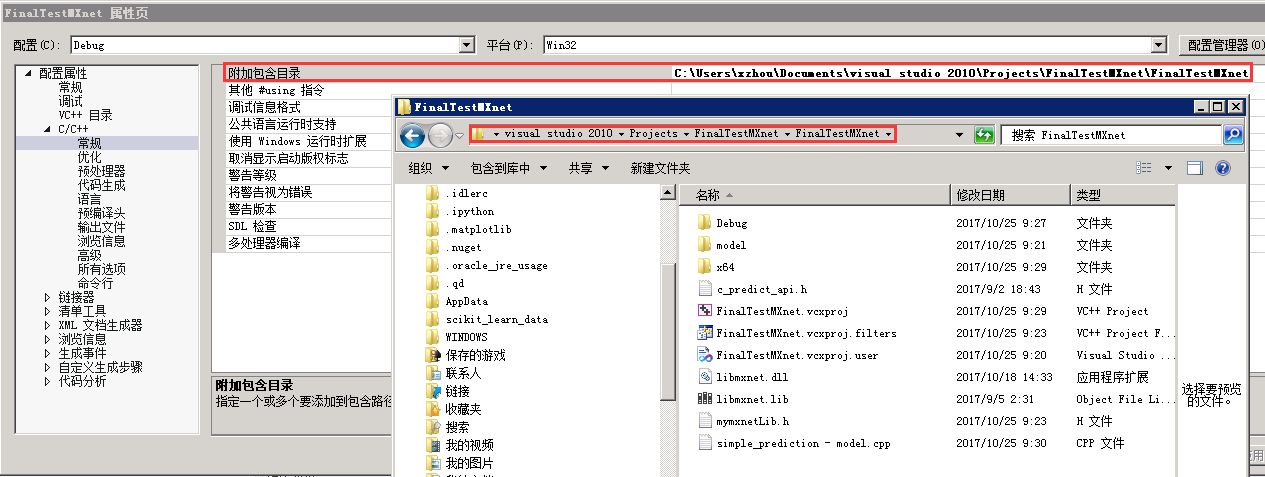
- 在链接器/输入中增加“附加依赖项”,即libmxnet.lib
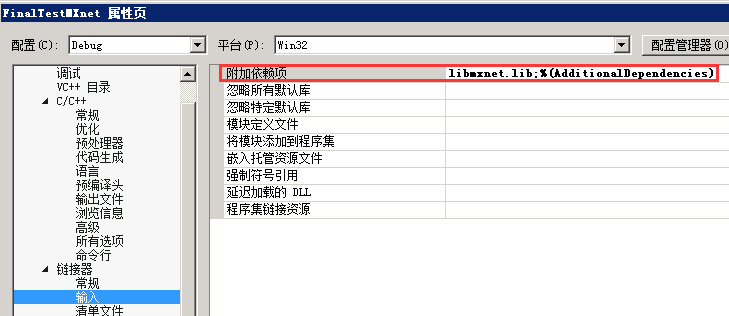
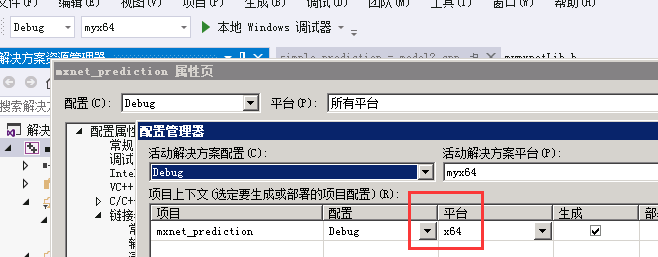
- 修改“活动解决方案平台”为x64
- 拷贝libmxnet.dll和libmxnet.lib和c_predict_api.h到工作目录
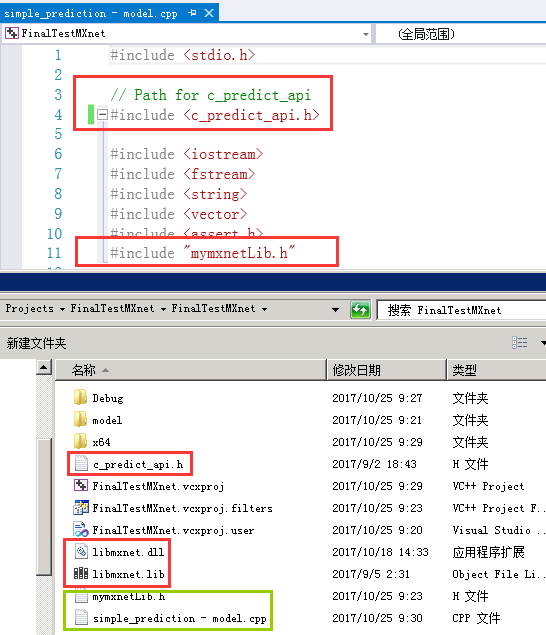
- cpp文件加入#include <c_predict_api.h>
- 拷贝libmxnet.dll和libmxnet.lib和c_predict_api.h到工作目录
C++使用指南
- 可运行单输入单输出 默认采用预测方式
- 可运行多输入多输出 默认采用预测方式
- 可运行多输入多输出 但是在输出端口可以只输出一个端口的数据
- 修改预测支持一个mini-batch只需要修改input_shape_data中的batch_size,并且将一个mini-batch的输入数据压平送进网络。在设置输入输出端口的vector的大小时候都要把它设置为一个batch数据长度的batch_size倍
利用HDF5文件做迭代器用于训练
1 | import mxnet as mx |
单输入单输出Seq2Seq模型
Python代码(HybridBlock版本)
1 | import mxnet as mx |
C++导入模型再预测 代码
1 |
|
简单的多输入多输出网络
Python代码(普通版本)
1 | from mxnet import nd |
Python代码(HybridBlock版本)
1 | from mxnet import nd |
C++导入模型再预测 代码
1 |
|
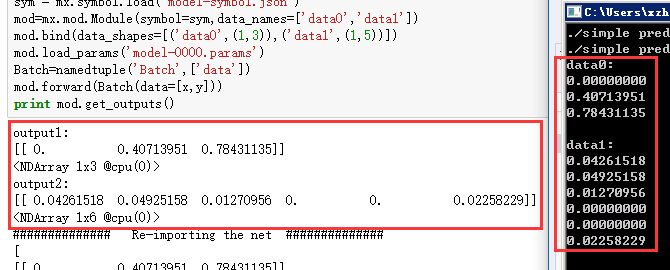
训练模板
单输入单输出
1 | import mxnet as mx |
导入测试
1 | import mxnet as mx |
多输入多输出
1 | import mxnet as mx |
导入测试
1 | import mxnet as mx |
MXNet源码阅读
io.py
位于E:\Anaconda\envs\gluon\Lib\site-packages\mxnet
阅读如何自定义迭代器